Cloud J-Flow Analysis
Overview of J-Flow Cloud Analysis
Cloud based J-Flow analysis is where key elements of J-Flow analysis solutions are deployed in public or private cloud environments. There are two major variants of cloud-based J-Flow analysis deployments: virtualized appliances and multi-tenant SaaS.
Virtualized Appliances**
The first form of cloud J-Flow analysis is achieved by deploying virtualized versions of classic J-Flow analysis elements, such as J-Flow collector and analysis appliances. In this model, when offered as a commercial service, separate virtual appliances are deployed in a cloud datacenter to handle each separate customer network. There are clear advantages to this model over hardware appliances, namely that it leverages commodity private or public cloud infrastructure and provides for flexibility in terms of changing the numbers of collectors or other virtual appliances to meet demand without the need to rack and cable new hardware.
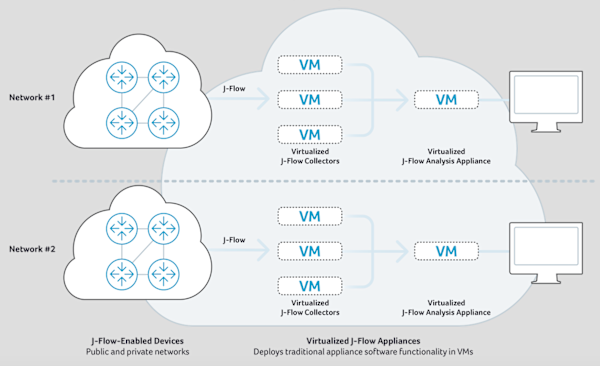
The limitation of this type of cloud-based J-Flow analysis is that it doesn’t actually harness the scale-out potential of true cloud computing architecture. Due to the relatively low cost-performance of scale-up appliance architectures, in practice, virtualized appliances hit very similar performance, storage, and analytical speed constraints as older hardware appliances.
Cloud-Scale/SaaS J-Flow Analysis
A second variant of cloud-based J-Flow analysis is one where the design is based on scale-out cloud computing principles. In this model, a cluster of computing and storage resources can scale-out on multiple dimensions. Servers are allocated to ingest J-Flow records, augment them with other related network data such as BGP and GeoIP, store them for processing, and support queries from analysis application clients. This approach insures that the capacity can be scaled flexibly to meet stringent performance requirements even as ingest and query rates grow significantly.
Cloud-scale computing has opened up a great opportunity to improve both the cost and functionality of J-Flow Analysis. From a functionality point of view, massive scale-out computing allows for the storage of huge volumes of augmented raw flow records instead of needing to roll-up the data to predefined aggregates that severely restrict analytical options.
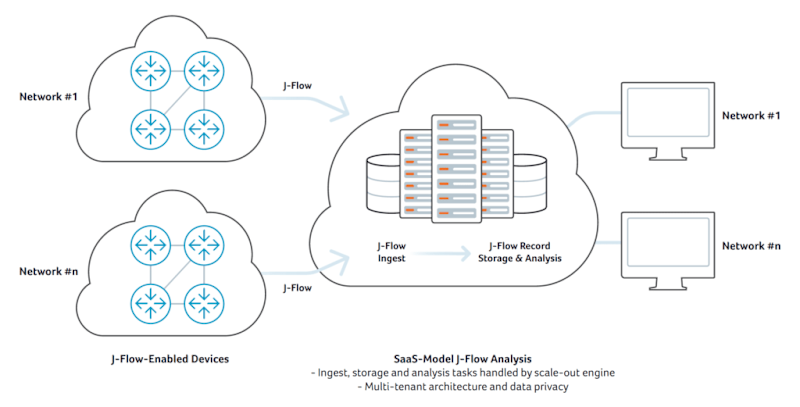
In a distributed scale-out model with sufficient compute and memory, J-Flow and other network telemetry such as BGP and GeoIP can all be ingested into a single time-series database. As each J-Flow record comes in, the system can look at its time stamp, grab the latest relevant BGP update from memory, and augment the J-Flow records using a variety of BGP attribute fields. With a cloud-scale cluster, this can happen in real-time for tens of millions of inbound flow records.
J-Flow analysis querying with instant response is key to operational utility. Engineers need to be able to look at aggregate traffic volume across a multi-terabit network, drill down to individual IPs and conversations, pivot views, filter and segment network traffic in any combination on-the-fly, so they can isolate the information that needs to be assessed to make effective decisions.
This type of performance requires a post-Hadoop big data approach more akin to that offered by Google Dremel/BigQuery. Many big data approaches to J-Flow analysis utilizes Hadoop technology to store and query J-Flow records using MapReduce. The key issues with Hadoop/MapReduce are the slow speed and fragility of creating data cubes to support responsive queries.
A ground-up cloud-scale J-Flow analysis design meets the scale, flexibility and response time needs of network operators. For example, a cloud-scale architecture can make data available for querying within a few seconds of ingest, as well as deliver answers to multi-dimensional, custom-filtered traffic analysis queries in a few seconds.
More Reading
To get other perspectives and details on Cloud-based J-Flow Analysis see…











